Retrieval-Augmented Generation(RAG) — The secret sauce to supercharge LLMs? 🧐⚡️
Introduction
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have emerged as a cornerstone. However, they’re not without challenges: hallucinations (generating incorrect or nonsensical information), lagging knowledge updates, and a lack of transparency in their reasoning processes. Enter Retrieval-Augmented Generation (RAG) — a cutting-edge solution that combines the deep understanding capabilities of LLMs with dynamic, external data retrieval. This synergy offers a more accurate, up-to-date, and transparent AI model.

What is RAG and why is it powerful?
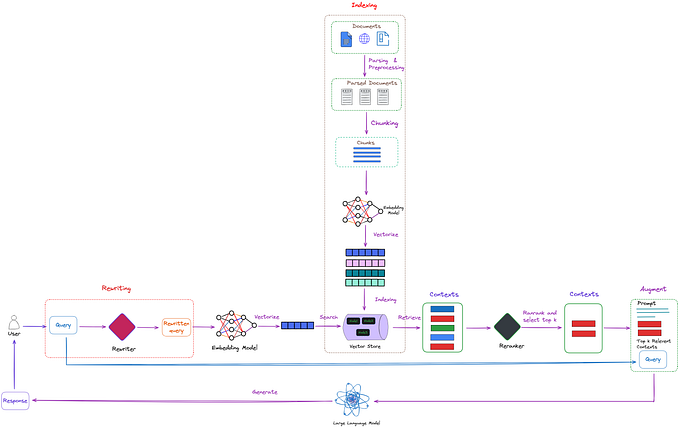
Retrieval-Augmented Generation (RAG) is an innovative approach in the field of natural language processing and artificial intelligence, particularly within the realm of large language models (LLMs). It effectively combines two major components: a retrieval mechanism and a generation mechanism, to enhance the capabilities of LLMs. Here’s a breakdown of how it works:
- Retrieval Mechanism: This part of the RAG framework is responsible for fetching relevant information from a large dataset or knowledge base. When the model receives a query or a prompt, the retrieval mechanism searches through available data to find content that is most relevant to the query. This process is akin to looking up reference material that can help in formulating a more informed and accurate response.
- Generation Mechanism: Once the relevant information is retrieved, it is passed to the generation mechanism. This part of the model is typically a language model, similar to those used in standalone LLMs. The generation mechanism uses the retrieved information to construct a response that is not only contextually appropriate but also enriched with the details from the retrieved data. This allows the model to provide responses that are more accurate, detailed, and up-to-date.
The key advantage of RAG is its ability to address some of the limitations of traditional LLMs. Standard language models generate responses based solely on the training data they’ve been fed, which can sometimes lead to outdated, inaccurate, or even nonsensical responses (a phenomenon known as “hallucination”). By integrating real-time data retrieval, RAG models can offer more accurate, relevant, and updated information.
In practical applications, RAG can be particularly useful in scenarios where keeping up with the latest information is crucial, such as in news aggregation, research assistance, and customer service bots. It enhances the language model’s ability to provide responses that are not just based on its training data, but also on the most current and relevant information available.

The Evolution of RAG: From Naive to Modular
RAG comes in three flavors: Naive, Advanced, and Modular.
- Naive RAG is the simplest form, where the model retrieves relevant information from a dataset and then generates a response based on this retrieval. However, it lacks the sophistication needed for complex queries.
- Advanced RAG steps up by integrating the retrieval process more closely with the generation, allowing for a more nuanced understanding and response generation.
- Modular RAG is the most sophisticated, offering customizable modules for different types of data and queries, making it highly adaptable to specific needs.
Understanding these paradigms is crucial for sales teams to articulate the adaptability and efficiency of RAG in various use cases.

When is RAG really needed?
In the dynamic field of AI, particularly with Large Language Models (LLMs), understanding when to employ Prompt Engineering, Retrieval-Augmented Generation (RAG), or Fine-Tuning is crucial. The decision largely hinges on the specific requirements of a task, particularly considering the need for external knowledge versus model adaptation.
1. Prompt Engineering: Leveraging Existing Model Knowledge
- When to Use: Prompt Engineering is most effective when the existing knowledge embedded within an LLM is sufficient to address the task at hand. This approach is ideal for scenarios where the model has already been trained on relevant data and merely needs guidance to extract and present this information effectively.
- Application Scenarios: It’s particularly useful in creative writing, generating general information, or when the task involves standard queries that the model is likely already familiar with based on its training data.
- Advantages: This method is cost-effective and quick, as it doesn’t require additional training or external data sources.
2. Retrieval-Augmented Generation (RAG): Integrating External Knowledge
- When to Use: RAG comes into play when the task requires information that is not part of the model’s original training data or when up-to-date information is crucial. It’s ideal for situations where the accuracy and relevance of responses depend on the latest data or specific knowledge that the model may not have been trained on.
- Application Scenarios: This approach is highly beneficial for tasks like answering current event questions, specialized queries in fields like medicine or law, or when detailed, specific information is necessary.
- Advantages: RAG provides a way to maintain the model’s relevance over time without the need for continuous retraining. It allows the model to access a vast range of external data sources, ensuring responses are current and detailed.
3. Fine-Tuning: Tailoring the Model to Specific Needs
- When to Use: Fine-Tuning is the method of choice when the model needs to be adapted to specific domains, languages, or styles that were not adequately covered in its original training. This is particularly relevant when there’s a substantial shift from the type of data the model was initially trained on to the data it will encounter in its intended application.
- Application Scenarios: Essential for tasks that require deep domain expertise, such as legal advice, technical support, or in-depth analysis in niche fields.
- Advantages: Fine-tuning allows for significant improvements in performance on specialized tasks by adapting the model more closely to the specific requirements of these tasks.
Making the Right Choice
The decision between these approaches depends on:
- Nature of the Task: Understand whether the task requires general knowledge (prompt engineering), up-to-date/specific information (RAG), or domain-specific adaptation (fine-tuning).
- Resource Availability: Consider the resources available, including time, computational power, and data. Prompt engineering requires minimal resources, while RAG and fine-tuning are more resource-intensive.
- Model’s Current Knowledge: Assess the current knowledge and capabilities of the LLM. If it aligns well with the task, prompt engineering might suffice. Otherwise, consider RAG or fine-tuning.


Measuring RAG’s Might: Evaluation Methods and Metrics
Evaluating the effectiveness of Retrieval-Augmented Generation (RAG) systems is a critical aspect of ensuring their reliability and utility in practical applications. Understanding the various methods and metrics used for this purpose is essential for teams looking to adopt RAG in their workflows. Here’s a detailed look at the key approaches and metrics for measuring the performance of RAG systems.
1. Evaluation Methods
Independent Evaluation:
- This method involves assessing the performance of the retrieval and generation components separately.
- For the retrieval component, evaluation focuses on the relevance and accuracy of the information retrieved in response to a query. Common metrics include Precision, Recall, and F1-Score.
- For the generation component, evaluation typically involves assessing the coherence, fluency, and relevance of the generated text. Metrics like BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are used.
End-to-End Evaluation:
This approach evaluates the RAG system as a whole, considering how well the retrieval and generation components work together to produce accurate and relevant responses.
Human Evaluation:
Involves human judges assessing the quality of responses in terms of accuracy, relevance, and informativeness.
Automated Evaluation:
Uses metrics like BLEU, ROUGE, and METEOR (Metric for Evaluation of Translation with Explicit Ordering) to evaluate the overall quality of the generated text.
2. Key Metrics for RAG Evaluation
- Accuracy: Measures how often the RAG system provides the correct information. It is vital in applications where factual correctness is paramount.
- Relevance: Assesses whether the retrieved information and the generated response are relevant to the query. High relevance is crucial for user satisfaction and system effectiveness.
- Fluency: Evaluates the readability and coherence of the generated text. Essential for ensuring that the responses are easily understandable by the end-users.
- Timeliness: Important in applications where up-to-date information is required. It measures how current the information provided by the RAG system is.
- Diversity: Assesses the variety in the responses generated by the RAG system. This metric is important to avoid repetitive or generic answers.

The Future of RAG: Expanding Horizons
The future of RAG lies in both vertical optimization (improving specific aspects of the model) and horizontal expansion (applying the model to a wide range of tasks). This versatility is vital in the AI ecosystem, as it allows RAG to adapt to various industries and use cases, from customer service to content creation. The future of Retrieval-Augmented Generation (RAG) appears to be a landscape marked by extensive innovation and integration, poised to significantly enhance the capabilities of natural language processing systems. One of the primary directions for RAG’s evolution is its deeper integration with increasingly diverse and dynamic data sources. This integration will enable RAG systems to offer even more accurate and contextually relevant responses, particularly in rapidly changing fields like news, scientific research, and social media trends. Another promising avenue is the development of more sophisticated retrieval mechanisms that can understand and process complex queries more effectively. Additionally, there’s potential for RAG to be tailored for specific industries, like healthcare or law, where accuracy and up-to-date information are crucial. In terms of technology, advancements in machine learning algorithms and computational power will allow RAG systems to become more efficient and scalable, handling larger datasets and more complex models with ease. Furthermore, as AI ethics and transparency become increasingly important, RAG systems will likely incorporate mechanisms to explain their retrieval and generation processes, enhancing trust and reliability. The integration of RAG with other AI technologies, such as predictive analytics and automated decision-making systems, could open new avenues for applications, making RAG a cornerstone technology in the next generation of AI solutions. The future of RAG is not just about technological advancements but also about creating AI systems that are more aligned with human needs, understanding, and ethical considerations.
🔖🤓 Liked this? Want to Read More📚👓
If you are from a startup or a product company you might like to explore my other loved articles:
- Gen AI Quick Reads #1: The Future of Software Engineering and What CEOs Can Do to Prepare
- Building basic intuition for Large Language Models (LLMs)
- Navigating the Costly Maze of Technical Debt
- 🚀 Product-led growth Vs 🤝 Sales-led growth for a B2B SaaS Product
- How to create ‘Aha! moments’ for your product users.
Feel free to drop in your Feedback or Connect with me on LinkedIn