How to do User Research Analysis

You’ve gone out and captured users’ experience data using whatever method you chose and now you’ve got a pile of recordings, transcripts, written notes and coloured stickies on a virtual board or office wall. What’s next?
There can be a great deal of pressure on the researcher to get the results ‘out there’ to stakeholders and decision-makers as soon as possible. I try to get into analysis at the earliest moment, sometimes running this alongside research sessions. I’ve been in the situation where stakeholders are meeting to discuss project / service directions and make decisions at the same time I’m rushing to get results written up before they reach any conclusions! The lesson here is the more time you can devote to analysis the better — it’s not something that can be done well in an instant!
A while back I was working on a contract for a public sector client where there was a real risk the recommendations from my extensive and complex user research programme would be ignored by stakeholders. This was about introducing a new digital service for thousands of people considered ‘vulnerable’ or otherwise severely disadvantaged in their ability and opportunity to lead normal lives.
The new service was intended to streamline and speed up the process of onboarding these people to a process that would provide (for those eligible) at least a minimum of support. The risk was that stakeholders would opt for a design more fitted to business needs than those of the intended service users. The research evidence was clear to this would lead to high levels of dropout and potentially incorrect applicant assessments. The advice I was given at this time by a stakeholder was that all I could do was deliver my research ‘playback’ and create a risk log.
Creating a risk log is good user research practice. But a risk log is like a contract — it’s kept in a metaphorical drawer and only brought out when there’s a problem. At which point, the user researcher can point the finger saying ‘I told you so.’ Not much help then to the immediate problem of those in need of some urgent support. That leaves the playback. The purpose of the playback is to report research results and recommendations based on our analysis of the data. Which means that the playback is a high stakes document, and our data analysis in terms of its validity and reliability is absolutely paramount.
Analysis is the part of the user researcher’s job that often gets skimped over in the research plan with vague references to affinity mapping, thematic analysis, or maybe even collaborative team analysis. One justification for being vague about methods of analysis at planning stage is quite simply to avoid pre-empting, pre-judging or pre-evaluating the data before you’ve even collected it. In other words, there’s no harm in being non-committal about how analysis will be done during research planning. That’s called being open-minded.
Findings vs. Insights
Let’s remind ourselves that the prime objective of doing research is to report findings and insights, on which your team is expected to act. The endgame is a better user experience for users and added value for the business. Analysis, in this sense, is the ‘acid test’ of the user researcher’s skills.
What exactly are findings and insights? Torresburriel Estudio (Medium, 2023) writes a neat piece explaining the differences between the two: a finding is a statement about what the user does, and an insight is the analysis bit which reasons why they do it. If you study a lot of user research playbacks what you are likely to see is a lot of findings being reported. There’s nothing wrong with that, providing you don’t call them insights. A finding is not an insight. It doesn’t tell you anything more than what the user does. Let’s unpick this a little.
Findings are accounts of what users do, how they do it, what context they do it in, and what pain points they endure. A CX or UX journey map that shows what a user does along with their experiential highs and lows at each stage of a particular task or group of tasks is a logical and tidy display of findings. It’s a good method for reporting findings from, for example, usability studies. The purpose of these kinds of studies is to find out how easily or not a user completes a task using a digital service, with CX/UX maps succinctly pointing out where the service is letting users down.
Insights are explanations of why the user does what they do. As such, it is reasoned speculation drawing on the data. You will most likely want to report findings and insights to give the fullest account of the people you’re interested in.
So, findings are a summary of the actions, context and experience of the user, and the insights are the explanation based on your analysis. Both can be connected right back to the raw data. This is an important point: researchers must be confident that findings and insights represent an accurate and reasoned summary of the data. Ideally you do this in a way that leaves the door open for anyone else (with appropriate permission of course — remember ethics and confidentiality) to review the source data and form their own analysis. In my experience, it’s rare that anyone does that (other than, of course, reviewing the data as part of a secondary research piece for another project). But this makes the point that there is no such thing as the perfect, single truth when it comes to data analysis. There is always scope for other possible interpretations. Your findings and insights are one version of the data — your version.
The problems of bias, subjectivity and objectivity
That brings me to another question — what of objectivity, subjectivity, bias and the role of the researcher? This is an important question and one that is usually only touched on, if at all, in the heat of the research moment.[1] I want to briefly dip into each of these, but first, a clarification. Biases are sometimes confused with heuristics: heuristics or ‘rules of thumb’ are mental shortcuts, mostly unconsciously done, to avoid cognitive overload. A psychological bias may include a heuristic, but they are not the same thing.
What is…..?
BIAS
Bias is an unconscious mental conclusion about a version of affairs and it comes in many guises. They are unconscious psychological phenomenon of which the thinker or experiencer is completely unaware in favouring this or that interpretation of events.
Functional Fixedness is one example of a bias where the perceiver (user, researcher) is fixated on one way of seeing a problem, for instance, restricting the availability of any other possible alternatives. I once referred to this as the Titanic bias — the Titanic’s passengers and crew automatically and unconsciously perceived the iceberg the ship tragically collided with as a threat and nothing else. An alternative view might be to see the iceberg as a solution to keeping out of the freezing sea.
Anchoring is another bias where, for instance, a research participant is unconsciously influenced in their response/reaction by information given by the researcher earlier.
Confirmation bias is a particularly live one for the user researcher. This is where the individual unconsciously searches for information that matches and confirms what they already think or believe to be the case. The most obvious example is attitude and belief about political figures. In the case of the user researcher, for instance, the risk is that confirmation bias will influence what they ‘see’ in their data when they start their analysis.
SUBJECTIVITY
This refers to a very large bundle of psychological phenomena including a person’s beliefs, attitudes, lived experience, preferences, knowledge, and so on.
Everything that a person has experienced and learned on their life travels influences how we ‘see’ and ‘understand’ phenomena. It is the essence of our individual identity and what makes us all individually different.
Becoming consciously aware of all these things is the attempt to think or act objectively.
OBJECTIVITY
To be objective, you need to be completely free of all biases, and that includes being free (that is, uninfluenced, consciously or otherwise, including physically) from any preferences, favouritism, benevolence or the opposite towards any and all phenomena involved. And that includes pre-conceived ideas, prior knowledge and experience.
So, without becoming caught up in a lengthy detailed set of explanations, it is impossible for any human being to be entirely objective. Decades of scientific research and study in psychology, cognitive psychology, social psychology etc. support this perspective.
If you won’t take my word for it, read Daniel Kahneman’s “Thinking Fast, Thinking Slow” (2011) or Kahneman and Tiversky’s Nobel Prize winning ‘Prospect Theory’ (1979). Or Bargh and Chartrand (1999)’s wonderful study of “The Unbearable Automaticity of being.”
So where does this leave the user researcher? Good question. I gladly step aside for Thomas Kuhn, one of the most distinguished and influential philosophers of the 20th century, to summarise: “…what you see depends on where you stand: perspective is all when it comes to knowledge and knowing.”[2] Researchers, according to Kuhn, cannot distance themselves from the object of their study and their methods and researchers come to their ‘laden with theory’. The attempt to be objective sounds like a lost cause.
You could try to identify and mitigate for any potential biases in your research — you should be doing this anyway particularly when developing your research materials and running your sessions. But when I say ‘mitigate’, all that can ever really be meant is ‘be aware of.’
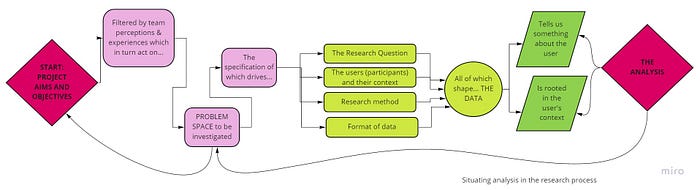
This diagram shows the typical workflow of a research project — at every single point there are opportunities for subjectivity and bias to creep in so that what might have started as a carefully crafted objective research question or hypothesis could become an unconsciously directed pathway straight to some (unconsciously) preferred conclusion.
But you can do more.
The solution is to include yourself as an active participant in the research action, along with any other team members involved in any aspect of your research (as collaborators in the research materials, or as observers/note-takers during sessions, for instance).
Think of it this way, you’re not just analysing what the research participant says, you’re extending this to include what you say, how you say it, how you respond — the actions you do. Taking this approach, the piece is seen as a conversational transaction in which each takes a turn at responding, requesting, evaluating, and so on. Logically, this makes complete sense. If you don’t include the user researcher — you — in the analysis, you would be analysing only half the story. Research sessions are transactions not one-sided monologues. Next, we look at how you can actually do analysis.
Ways and methods for good analysis
You will find a summary and description of some of the methods of analysis, mostly dealing with qualitative data, that can be used in user research at the end of this blog. The way that data is analysed typically depends on the research question, the research method and the type of data captured.
Almost any method of analysis has the same 4 simple steps:
In user research the starting point for analysis is often a bunch of coloured stickies (we’ll call them data points) on a wall or virtual board with each containing a snippet of information or a participant quote from the research sessions. Or, you might be using a research application like Dovetail, Optimal Workshop or Nvivo in which case you’ll be looking at transcripts of sessions with the aim of identifying and extracting data points of interest. In all cases, the steps have more or less the same principles.
Before you get stuck in, a couple of pieces of advice:
· The object of the exercise is to answer the research question or to support/invalidate the research hypothesis — in either case, this should steer everything you do. It’s a good idea to put that question or statement at the top of your board in big bold letters!
· Data only has meaning when seen in its context. Ensure your data is colour-coded and/or tagged (using participant ID rather than actual name, of course) to connect it to specific participants. That way, you’re able to trace each data point or quote right back to the source if needed. Also, where you have more than one data point from the same participant that are related in some way, make sure they’re linked so you don’t lose that connection and context.
Walking through each step one at a time:
PREPARE: Prepare and arrange your data into initial groups such as by interview question or theme. The logical method of arrangement for usability testing data is by each stage or activity or screen in the session task. Data points from interviews can be arranged according to each question or theme under discussion. Howsoever you do it, the starting point for analysis is to have the data points displayed in such a way that you can easily move to and fro across the data, comparing, contrasting, exploring.
REVIEW/EXPLORE: Review data for e.g., high level stories, an overall description or summary of the data — what is it ‘saying’. This is where the researcher starts to form some ‘gists’ or hunches about what’s going on in the data. Bearing in mind the research question or hypothesis, what is the data ‘saying to you’, how is it making you feel, what story is emerging? Depending on how much data you have to play with this step can take 5 minutes or several hours. The idea is to start to form some early notions of the kinds of big themes, indicators, impressions that reviewing the data is giving you. Now you’re reading to start coding.
CODING: Code the data e.g., according to recurring themes of interest, outliers, emerging concepts. This is an important step towards analysis but it is not analysis. What you are doing here is starting to group, categorise or otherwise organise all your data points according to recurring themes, sentiments, evaluations, personal skills and abilities such as digital skills levels — in fact anything that’s relevant to the research question or hypothesis BUT which are what you see in the data itself and not what you assume. You might end up with one theme called ‘Low Digital Skills’ and other called the opposite, or groups according to participant position in different stages of a process such as applying for a VISA. Groups could be about how participants perceive changes needed to improve the outcomes of a particular project, or experience of a particular application process.
Taken together, ALL THREE OF THESE steps is popularly known in user research as ‘Affinity Mapping’. Affinity mapping is not analysis — it is coding. Here’s a couple of other common misconceptions:
· Counting and reporting the number of times participants use certain words or phrases is not analysis — it’s counting!
· Counting and reporting how many participants say or do this or that is not analysis, it’s a finding.
In both these examples, the user researcher risks applying a quantitative analysis method to qualitative data. Quantitative data and methods of analysis are wholly different from those in qualitative research. Researchers should not mix the two, and resist the temptation (I know, I’ve been there myself!) to report things like ‘5/6 participants were able to complete the task within time’. Or even worse, convert that to a % and report it. Why? Because quantitative data is all about significance and probability. Research aims to report results that can be shown to have a high level of confidence, based on analysis, that if generalised to an entire relevant population the results would be the same.
ANALYSE: Analyse data for e.g., patterns, consitencies vs inconsistencies, recurring but varying themes or perspectives, what’s there vs what’s absent, anomalies, assumption etc. Finally, we’re ready to analyse our data. Think about your research question or hypothesis and perhaps jot down some key values or attributes that you’re looking for in your data. Think about your participants — who are they, what context are they working/living/interacting/engaging within? What are they trying to do and why? What pain points are they experiencing? What kind of data are you dealing with? What are you hoping to output as a deliverable, for instance, a user journey map, personas, user stories, a low granularity service design, or a straightforward presentation of key findings and insights?
Here’s a bit of Discourse Psychology for you. As you start to interrogate your data, it’s a good idea to bear in mind two important considerations. First, when people speak, they speak from a position — a manager, software developer, creative designer, delivery manager, wife, mother, father and so on. That means they have a vested interest — a stake — in what they are saying, the stories they tell, the opinions they express etc. So, given that, what are they doing with their words?
Second, when we talk or write, we are creating version of reality unique to ourselves. While we might talk of events as factual, as what actually happened for all to see, we all ‘see’ things differently. Two people can stand in the same place and look at the same tree, but they will both ‘see’ different things. When telling our colleagues stories, describing events in a user research session for instance, we are not just recounting what happened, we are persuading, blaming, elaborating, down-grading. These are all behaviours. So, thinking about a discovery interview, the participant isn’t just making statements in response to your questions, they are behaving — doing actions with their words — in the same way they do action when clicking a mouse. So, what are they doing and why are they doing it?
Approaching qualitative analysis with these considerations in mind is one pragmatic way of addressing the thorny issues of bias and subjectivity head on.
Example:
Participant: “Most of my clients have absolutely no idea of what to expect when they need to make a small claim through the courts. So I have to spend quite a bit of time up front explaining what’s involved, each step of the process.”
You: “Why do you think that is?”
Participant: Well, it’s not easy for members of the public to find that kind of information.
The participant in the example is a lawyer. The first thing to notice is that she clearly differentiates herself from ‘member of the public’ and categorises herself as someone with privileged access to important information. One interpretation is that she’s justifying herself as a solicitor — someone who is essential if people are to do what they want to do. The public can’t make a claim without her — or someone like her. Notice also how she answers the ‘why’ question with a statement of fact. Who’s not making it easy for the public? Who’s standing in the way and failing to give the public the information that they need? So there’s blaming going on. Who is she blaming?
You see how a simple interrogation of the dialogue between participant and researcher can reveal a richer insight into motivations, positioning, actions of blaming and so on.
Take a bird’s eye view of your data and start to think about some of the following kinds of questions:
Zoom out from the groupings and look at the arrangement and concentration of colours — what is this telling me?
With interview data for instance, you might notice a concentration of data points around one or more question or topic. Less amongst others. What’s going on? Are participants dwelling more on some topics rather than others? Why might that be? What does that mean? Are some topics or questions showing up as more salient than others? Compare and contrast the extremes.
What are participants NOT saying?
What’s missing in the data. Are there any obvious gaps in what participants say in answer to questions or prompts?
If your data points represent actual words spoken, what verbs and adjectives are they using and with what effect?
This is not about doing word counts — counting the number of times a word features in participants’ talk is high level content analysis which can’t tell you much other than that this word or that word appears more frequently than possible alternatives.
This is about paying attention to how participants talk about topics — perhaps a higher level of description / explanation is given to some more than other topics. Why? It might suggest that the topic is not well understood, that they frequently feel compelled to provide more elaborate statements, justifications and so on than with other topics.
What are they doing with their words — what ‘actions’ are they doing? E.g., blaming, excusing, creating contingencies, applying extreme emphasis to an expressed opinion and so on.
The basis of this question is simple: think of words, sentences, ‘utterances’ as action. Spoken words are doing something — making an excuse, hedging (bets), blaming, praising, displaying some emotion and so on.
Say, for instance one participant states: “I’m enjoying my job and am good at it, but the stakeholder on the project is…(a negative assessment).” What are they doing? Perhaps they are mitigating future failure in doing their job — it’s the stakeholder’s fault. We call this warranting — for instance, through their talk people ‘create a warrant’ for not doing a good job — it’s not their fault but someone else’s.
Then you ask yourself: why is this person doing that? What effect is that having? This is discourse analysis.
What assumptions am I making?
Here what you’re interested in is why those assumptions and not others? Where are those assumptions coming from? What is it in the data that is causing you to form those assumptions?
How does this data make me feel?
When reviewing individual data points, observe and make explicit how this is making you feel? Ask yourself, why is that? ‘How is it making me feel this?’
KEY TAKEAWAYS
· Qualitative and quantitative research involve different skills sets, methods and have different objectives. They can compliment one another, but they are different and methods should not be mixed.
· Findings are statements of action — what happened, what the user does — while insights are explanations of why based on analysis of the data. The objective of user research is to understand what users do and why so a complete outcome from research is to have both findings and insights.
· Data analysis has four main stages: Prepare, Review & Explore, Code and Analyse. The first three are preparatory stages with Coding, for instance, where you might reach a set of findings. To generate real, justified and valid insights, you should apply all 4 stages.
· When approaching analysis of qualitative data, keep in mind that people are all individually different. When they speak, whether to answer a question, tell a story or present research findings, we are actively speaking from a position of stake and interest, and constructing a version of reality as we individually see and understand it. The skill of the user researcher is to communicate this responsibly, reasonably and persuasively to build shared empathy with stakeholders, decision-makers and team members. That’s our value.
I am Lesley Crane and I am a User Researcher.
SUMMARY OF SOME PRIMARY METHODS OF ANALYSIS IN USER RESEARCH
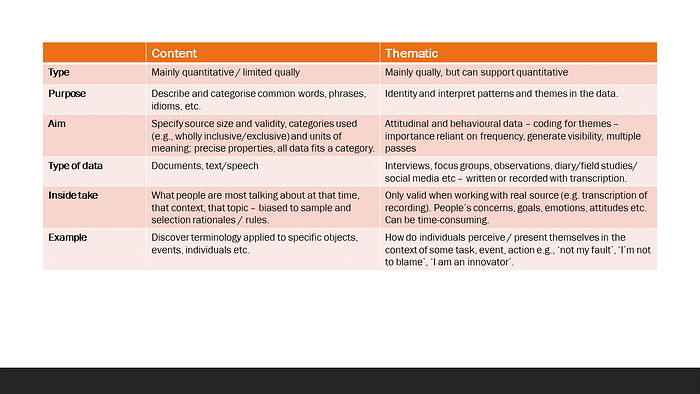

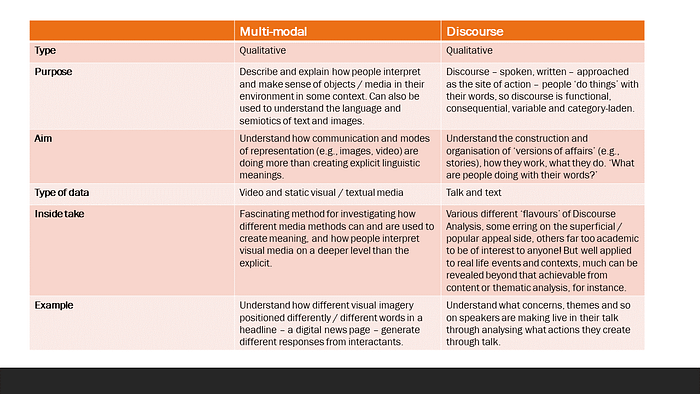
[1] See “User Research Interviews: the unbearable impossibility of being objective and how to mitigate subjectivity” and “User research — beyond affinity diagrams.”
[2] Kuhn, T. (1962). The Structure of Scientific Revolutions, 3rd Edn. Chicago: University of Chicago Press

