Getting geeky 🤓: Data sampling collection types and when to use them

Article by Jason Stockwell, Digital Insight Lead at People for Research
Quick disclaimer before we start: Data sampling is simple, it is the method in which we choose a sample group of participants to take part in research. But it’s also one of the most important steps of your research process and it’s essential that we understand the importance of data sampling to ensure we get a balanced perspective.
One of the problems with the term data sampling is it’s putting together two things that aren’t very cool and trying to make them seem cooler.
A different issue is that we sometimes take this step without thinking about it, picking and choosing the participants we want to take part and not thinking about the opinions of those that “don’t matter” to us.

We’re constantly told to find the right target audience for user research, but with more need for inclusivity and accessibility in research, the idea of random sampling needs to fit the needs of these groups for better outcomes and accessible product design.
We’ll talk a bit about this later on, but if we’re looking at optimising inclusivity, does this take away from random selection for research?
There isn’t one right way of choosing an audience, but most times it is all about using the right horses for the right courses. I don’t like that phrase, but it makes sense in this context.
There are obvious data sampling types to avoid — like only picking the people whose opinions confirm your assumptions — , but there are also more complex data sampling methods that are worth considering. Let’s take a look at them.
🔀 Random vs non-random
The first question to ask is: are you picking participants for your research based on information you know about them/they have provided or are you getting participants from a random pool?
Random sampling
We’ll start with random sampling, as there are fewer variations here. Random sampling is a technique where each participant from a pool has an equal probability of getting selected. Even if multiple participants are screened before the research, this participant pool is randomised and respondents are selected to take part.
Random sampling is unbiased and simple, but it isn’t always the best approach for pre-qualification and inclusivity. Random samples are only as good as the participant pool you are fishing from. There will be participants that are better suited than others in a research pool, and minority groups that are missed out by random selection. You still need to ensure the original sample size is representative of the wider population and also inclusive of minority groups.
Let’s go ahead with two examples of different random sampling methods.
With a simple random sample, we want the opinions of our top 500 customers, let’s assign each individual a random number and contact the first 15 customers to take part in a research session.

This is as random as it gets, but it isn’t representative. From the example above, you can see that the lightest blue participants were selected for 40% of the research slots, despite only having 14% of the population. Let’s see if a different approach ensures “organised randomness”.
Introducing stratified sampling:
If we were to calculate the percentage of customers that match a specific industry, let’s say we have 40% retail customers and 60% hospitality. We want to split out these industries and give the customers a random number again. This way we can ensure we get an even split of retail and hospitality businesses to give valuable feedback for each.

Random sampling helps ensure the research is valid by limiting bias in recruitment.
Non-random sampling
Non-random sampling feels like playing the same sport, but with different rules. With non-random sampling, the selection is not based on chance, but on factors chosen by the researcher. These factors can be as simple as convenience or previous experiences, but can also add elements of bias to the process.
Let’s dig a little bit deeper into some examples of non-random sampling and when they occur in user research:
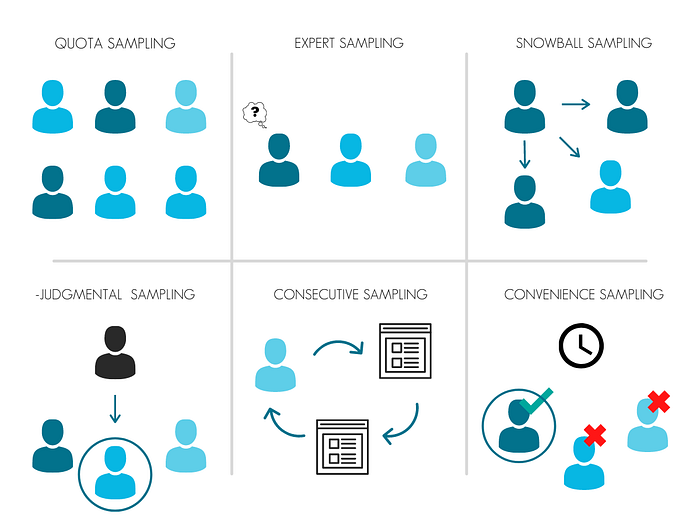
Quota sampling
This is something we all fall into: fitting participants into boxes because we need an opinion of an individual who is part of a specific demographic. This is excellent for inclusivity, but it does mean we are treating participants as numbers and not people.
Expert sampling
Another useful sampling option when dealing with complex projects is only selecting experts in a topic or field. This is hard to avoid when talking about complicated topics, but if your end goal is to simplify language, then it is better to get less experienced participants involved.
Snowball sampling
Snowball sampling works by getting referrals to take part in research. Asking a participant to refer someone to take part in research seems like a great idea, but too often this means we end up with participants that all share a similar viewpoint.
Judgmental sampling
This is the opposite of expert sampling, where researchers only select participants they deem fit to take part in the research. As this is reliant on the researcher’s opinion, this is open to ambiguity and bias.
Consecutive sampling
The diary study often falls victim to this, selecting the same individual for repetitive research increases their familiarity with the topic or product, but gives you limited points of view.
Convenience sampling
Samples are selected based on their availability. Excellent for our convenience, but the busiest and time-poor participants, especially in B2B recruitment, often get overlooked.

There are benefits to both types of data sampling, but the most commonly used in qual research tends to be non-random sampling. With more in-depth research, we’re looking for checkboxes and specific demographics. After all, there isn’t a lot of point in interviewing participants that are never going to use our products or won’t be able to answer our questions!
Even for quant research, we want to pre-qualify participants — sometimes to ensure it is random — , but this organised randomness takes away from a truly random audience.
What data sampling methods have you found work for you? Let me know how you get on! And if you need any help or have questions about using the right data for surveys, you can find out more information here.

We want to keep in touch! Join People for Research mailing list to receive our newsletter and/or our monthly round-up.


